[딥테크] AI 올림피아드 성과, 교육이 풀어야 할 과제는 추론 문해력

입력
수정
IMO 성과는 범용 지능이 아닌 특정 영역 성취 무응답 기능이 오답 줄이며 안전장치로 작동 교육은 정답률보다 추론·이해 역량 강화에 집중
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Business Review 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.
2025년 7월, 구글 딥마인드(Google DeepMind)와 오픈AI(OpenAI)가 개발한 인공지능(AI) 시스템이 국제수학올림피아드(IMO)에서 처음으로 금메달 수준의 성적을 거뒀다. 제한 시간 4시간30분 동안 출제된 6문제 가운데 5문제를 해결한 결과다. 지난해까지만 해도 딥마인드의 모델은 은메달 수준에 머물렀다는 점을 고려하면 뚜렷한 진전이다. 그러나 인간 참가자들의 성취는 여전히 높았다. 전체 630명 중 약 11%가 금메달을 획득했으며, 일부 학생들은 AI보다 높은 점수를 기록했다.
이번 성과는 범용 지능 도달을 의미하기보다는 특정 조건에서 문제 해결 능력이 향상된 사례로 평가하는 것이 타당하다. 특히 불확실할 때 답변을 회피하는 ‘선택적 무응답’ 기능이 정확도를 높이는 데 기여했다.

수학 경연 성과, 현실 문제는 한계
IMO 금메달은 종종 인공지능이 인간과 유사한 범용 추론 능력에 도달했다는 신호로 해석된다. 그러나 실제 의미는 제한적이다. 이번 성과는 문제를 단계적으로 전개할 수 있고, 체계적 탐색이 가능하며, 정답 여부가 명확히 판정되는 영역에서 발휘된 것이다. 고난도 수학 경연이 바로 그러한 성격을 지닌다.
딥마인드가 2024년 은메달 수준에 도달했을 때는 기하 전용 엔진과 형식 검증기를 결합해야 했으며, 2025년에는 언어 기반 추론과 모듈형 체계를 통합해 새로운 문제에서도 금메달 수준에 올라섰다. 그러나 이러한 성취가 곧바로 현실 세계의 불확실하고 정답이 모호한 문제 해결로 이어지는 것은 아니다.
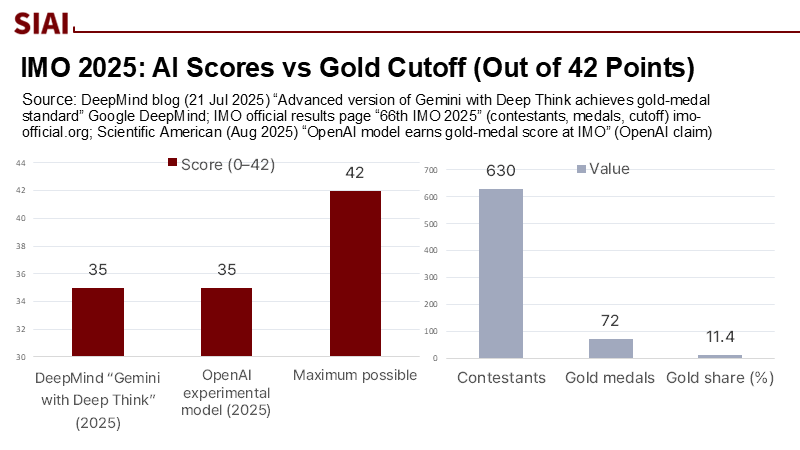
주: (왼쪽 그래프)점수 비교 — X축(딥마인드, 오픈AI, 만점), Y축(점수, 0~42점)/(오른쪽 그래프) 금메달 비교 — X축(참가자 수, 금메달 수, 금메달 비율), Y축(값)
오답 대신 무응답, 안전장치로 작동
이번 성과에서 눈에 띄는 부분은 답변 거부 기능이다. 기존 시스템은 정답이 아닐 때도 단정적인 풀이를 제시했지만, 최신 시스템은 내부 불일치가 감지되면 답변을 내지 않는다. 수학에서는 오답보다 무응답이 낫다. 증명은 즉시 옳고 그름이 판정되기 때문이다.
최근 연구는 이를 ‘정형 제외(conformal abstention)’ 기법으로 정식화했다. 모델이 여러 풀이를 생성해 자기 일관성을 평가하고, 이 과정에서 오류 가능성을 통계적으로 제한한다. 2025년 발표된 후속 연구에서는 학습을 통해 설정된 거부 규칙이 위험한 출력 탐지 능력을 강화한다는 점도 확인됐다. 불확실할 경우 답변을 거부하는 절차가 금메달 수준 성과를 뒷받침한 것이다.
증명 데이터 확산과 그 한계
이번 성과의 또 다른 배경은 증명 데이터의 확산이다. 린(Lean)과 같은 형식 증명 언어를 활용한 대규모 데이터셋, 자동 형식화(autoformalization) 파이프라인, 검증기를 결합한 학습 방식이 빠르게 발전했다.
딥식 프로버(DeepSeek-Prover) 프로젝트와 후속 연구는 모델이 대회 수준의 문제에 대해 기계가 확인할 수 있는 증명을 산출할 수 있음을 보여줬다. 모든 풀이가 기계적으로 검증되면서 오류 가능성은 줄었다. 그러나 이는 새로운 발견을 의미하지 않는다. 아직 정립되지 않은 정리나 미해결 추측에 직면했을 때 모델은 기존 보조정리를 재조합하는 수준에 머문다.
따라서 이번 성과는 학생들에게 건전한 추론의 예시와 즉각적인 피드백을 제공하는 도구로서 의미가 있다. 다만 ‘증명을 제시한다’라는 능력을 곧바로 ‘새로운 지식을 창출한다’라는 능력으로 확대 해석해서는 안 된다. 인공지능이 새로운 수학적 발견을 주장할 경우 외부 증명 기록과 독립적 재현 절차가 반드시 뒷받침돼야 한다.
학력 하락과 AI 역량의 동시 전개
AI 역량이 빠르게 높아지는 시점은 전 세계 학력 저하와 맞물려 있다. 국제학업성취도평가(PISA) 2022에서 수학 점수는 평균 15점 하락해 약 1년 치 학습 후퇴로 평가됐다. 미국 전국학업성취도평가(NAEP) 2024 결과에서도 초등 4학년은 일부 회복세를 보였지만 2019년 수준에는 미치지 못했고, 중등 8학년은 사상 최저 수준에서 정체됐다.
수요가 늘어나는 상황에서 공급은 부족하다. 미국에서 교사 부족을 호소한 교장은 2015년 29%에서 2022년 47%로 늘었고, 세계적으로는 2030년까지 약 4,400만 명의 교사가 부족할 것으로 전망된다. 이러한 상황에서 이번 성과를 범용 지능 도달로 오해할 경우 교육 현장에 잘못된 적용으로 이어질 수 있다. AI는 반복적인 채점과 단계별 풀이 지원을 담당하고, 교사는 전략적 해석과 사고 과정 지도를 강화하는 보조적 활용이 바람직하다.
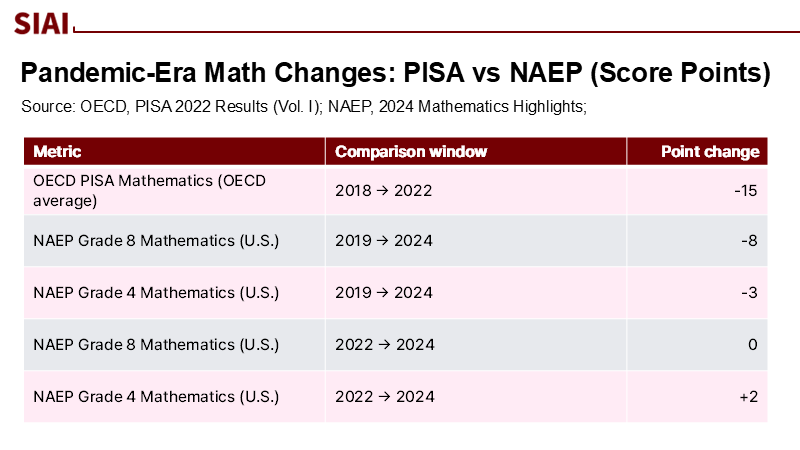
주: OECD PISA 수학 (OECD 평균), NAEP Grade 8 수학 (미국, 중2 수준), NAEP Grade 4 수학 (미국, 초4 수준), NAEP Grade 8 수학 (미국, 단기 비교), NAEP Grade 4 수학 (미국, 단기 비교)
정답률보다 추론 과정이 핵심
이번 성과의 의의는 범용 지능에 있지 않다. 인공지능이 제공하는 진정한 가치는 학생들이 문제 풀이 과정의 추론을 눈으로 확인하며 학습할 수 있다는 점이다. 학생들은 증명 과정에서 오류를 직접 찾아 수정하고, 그 결과를 다시 검증받을 수 있다. 따라서 성과 지표는 단순한 정답률이 아니라 개념 이해와 적용 능력이 돼야 한다. 불변량을 인식하고, 보조정리를 적절히 선택하며, 특정 전략의 타당성을 설명할 수 있는 능력이 그 핵심이다.
다만 수학 이외의 영역에서는 정답이 불명확하다. 설명은 확률적이거나 논쟁적일 수밖에 없다. 따라서 거부 기능, 분야별 검증 도구, 교사의 불확실성 지도 역량이 반드시 병행돼야 한다.
과장된 기대보다 추론 문해력 확산
인공지능이 높은 성과를 낼 수 있었던 배경은 정답이 명확히 검증 가능한 좁은 영역에서 체계적 탐색과 절제 전략이 작동했기 때문이다. 앞으로 필요한 것은 과도한 기대가 아니라 명확한 원칙이다. 결과를 검증 가능한 기록으로 남기고, 불확실할 때는 답변을 거부하며, 새로운 성과는 독립적으로 재현돼야 한다.
지금 교육이 추구해야 할 과제는 범용 지능이 아니라 추론 문해력의 확산이다. 추론 과정을 이해하고 활용할 수 있는 능력이야말로 인공지능 시대에 요구되는 진정한 성취다.
본 연구 기사의 원문은 Gold Isn't General: Why Olympiad Wins Don't Signal AGI—and What Schools Should Do Now을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.
- Previous "수수료 탈출, 브랜드 독립" 소상공인 자사몰 도전의 명암
- Next [딥테크] 관세가 일자리 보호한다고?