[딥테크] ChatGPT, 시작 도구일까 최종 답안일까

입력
수정
생성형 AI의 신뢰성 문제 교육 현장에서 필요한 활용 지침의 부재 평가 방식과 정책의 재설계 필요
본 기사는 The Economy의 연구 팀의 The Economy Research 기고를 번역한 기사입니다. 본 기고 시리즈는 글로벌 유수 연구 기관의 최근 연구 결과, 경제 분석, 정책 제안 등을 평범한 언어로 풀어내 일반 독자들에게 친근한 콘텐츠를 제공하는데 목표를 두고 있습니다. 기고자의 해석과 논평이 추가된 만큼, 본 기사에 제시된 견해는 원문의 견해와 일치하지 않을 수도 있습니다.
2025년 퓨리서치센터(Pew Research Center)는 미국 성인 37%가 웹 검색을 구글이 아닌 ChatGPT에서 시작한다고 발표했다. ChatGPT가 검색 도구처럼 활용되고 있다는 뜻이다. 같은 해 생성형 AI 평가 플랫폼 벡타라(Vectara)와 허깅페이스(Hugging Face)는 GPT-4o-mini가 생성한 답변 가운데 1.7%에서 허위 정보가 포함됐다고 밝혔다. 일부 전문 분야에선 오류율이 40%를 넘기도 했다. 아이디어 정리에 강점이 있는 ChatGPT는 초안 작성에는 유용하지만, 정보의 신뢰성 측면에선 여전히 보완이 필요하다. 결국 핵심은 사용 방식이다. 사고의 출발점으로 활용하되, 최종 판단과 검토는 사람이 직접 해야 한다는 원칙이 요구된다.

검색이 아닌 사고의 출발점
대형 언어모델(Large Language Model, LLM)은 구글을 대신해 지식 작업의 시작점이 되고 있지만, 역할은 다르다. 검색은 정보를 찾고, ChatGPT는 정보를 예측해 조합하며 때론 사실과 다른 내용도 만든다. 사이언티픽 아메리칸(Scientific American)은 이런 현상이 정보 회상 능력의 외주화로 이어질 수 있다고 경고했지만, 실제로는 초기 사고 과정을 빠르게 시작하는 전략적 선택에 가깝다.
문제는 이러한 활용이 빠르게 확산되고 있음에도, 현장에서는 이를 반영한 제도적 기준이 부족하다는 점이다. 미국 경제연구국(National Bureau of Economic Research, NBER)에 따르면 직장에서의 ChatGPT 활용은 6개월마다 두 배씩 증가하고 있다. 반면 대학 상당수는 여전히 ‘표절 금지’ 수준의 경고만 있을 뿐, 학습 활동에 ChatGPT를 어떻게 활용할 수 있는지에 대한 구체적인 지침은 부재하다. 그 결과 학생들은 AI가 작성한 문장도 검증된 자료처럼 받아들이는 오류에 빠질 수 있다.
정확도와 신뢰의 간극
GPT-4o의 정보 정확도는 여전히 제한적이라는 분석이 나온다. 벡타라(Vectara)의 오류 평가 리더보드, 챗베이스(Chatbase)의 신뢰성 테스트, 익스프레스리걸펀딩(Express Legal Funding)의 조사, MIT의 뇌파 실험 등 네 가지 자료를 종합하면, GPT-4o는 2023년 이전 정보에 대해 평균 92.6%의 정확도를 보였지만, 한 달 이내의 최신 정보에 대해서는 69.4%에 그쳤다. 인용 오류는 더 심각하다. 학술 플랫폼 텐드폰라인(Tandfonline)은 GPT-4o가 생성한 연구 요약의 51.8%에 허위 인용이 포함됐다고 분석했다.
이런 한계는 ChatGPT를 사고의 보조 도구로만 제한해야 하는 이유를 뒷받침한다. 글의 초안을 빠르게 구성하는 데에는 유용하지만, 검증되지 않은 AI 결과물을 그대로 받아들이는 순간 정보 왜곡 가능성이 커진다.
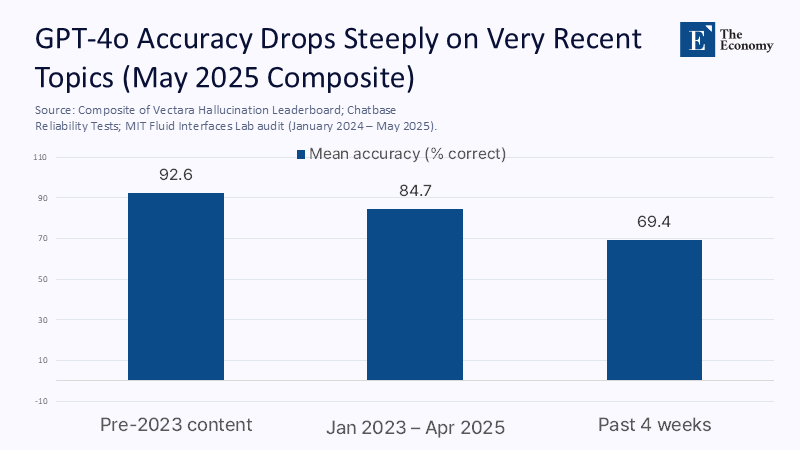
주: 시간 구간(X축), 정확도(Y축)/2023년 이전 정보, 2023년 1월 ~ 2025년 4월, 최근 4주간(좌측부터)
사고력은 어디서 자라는가
그럼에도 이 도구를 사용하는 이유는 분명하다. 바로 ‘속도’다. 스트래튼 애널리틱스(Stratton Analytics)가 분석한 결과, GPT형 초안 도구를 활용한 팀은 문서 작성 시간을 평균 23% 단축한 것으로 나타났다. 오하이오주의 고등학교 시범 사업에서도 비슷한 결과가 나왔다. 평균 글쓰기 시간이 4.6시간에서 3.1시간으로 줄었지만, 평가 점수에는 유의미한 차이가 없었다. 즉, 절약된 시간이 교육적으로 의미 있으려면, 그 시간만큼 사고와 검토에 다시 투자돼야 한다는 뜻이다.

주: 활용 방식(X축), 작성 시간 및 점수(Y축)/AI 미사용, ChatGPT 개요 사용, ChatGPT 전체 작성(좌측부터), 평균 작성 시간(진한 파랑), 에세이 점수(연한 파랑)
ChatGPT의 활용 범위에 따라 학습 효과도 달라진다. 미국의 한 커뮤니티 칼리지에서 ChatGPT를 개요 작성에만 활용하고 본문은 직접 작성한 학생 87명을 추적한 결과, 이들은 AI에 전체를 맡긴 그룹보다 전이형 사고 문제에서 평균 0.42 표준편차 높은 점수를 기록했다. 이는 ‘논증’이 아닌 ‘구조’에 AI를 활용할 때 인지적 이득이 크다는 뜻이다. 실제 수업에서는 마인드맵, 자료 설계, 반론 정리 등 사고의 초기 단계에만 ChatGPT를 활용하고, 논지 구성이나 사실 검토는 직접 수행하도록 하는 방식이 효과적이다. 작업 흐름에 이런 구분을 도입하면, 시간은 절약하되 검증 능력은 키울 수 있다.
AI 의존이 아닌 사고 훈련으로
AI와 함께 글을 쓰면 두뇌 활동이 둔화된다는 우려도 있다. MIT의 뇌파 실험에 따르면 ChatGPT를 활용할 때 전두·두정엽 간 뇌 연결이 32% 감소했다. 하지만 나중에 AI가 낸 오류를 비판하도록 요청받았을 때는 대조군보다 12% 더 활발한 뇌 활동이 나타났다. 이는 계산기 도입 초기와 비슷한 흐름이다. 암산 능력은 낮아졌지만, 개념 수학 성적은 오히려 상승했다. 반복 작업을 도구에 맡기고, 인간은 추론과 검토에 집중하는 방식이다. ChatGPT 역시 일상적인 정리 작업은 맡기고, 확보된 주의를 사고에 집중하도록 활용할 수 있다. 단, 책임 있는 활용을 위해선 학습자가 결과물에 관해 설명하고 검토할 수 있어야 한다. 구술 발표, 과정 일지, 주석 참고문헌 같은 절차가 필요한 이유다.
제도화되는 ‘보조 전용’ 원칙
AI 도구의 안전한 교육 활용을 위해선 구체적인 정책 기준이 필요하다. 먼저, 교실에서 사용하는 AI 플랫폼은 출처와 생성 이력을 투명하게 공개해야 하며, 그렇지 못한 경우엔 아이디어 구상용으로만 사용을 제한해야 한다. 오하이오주의 한 시범학교는 AI 도움을 받은 과제에 150단어 분량의 활용 설명서 제출을 의무화한 뒤, 표절률을 38% 낮추고 글의 완성도를 높이는 효과를 봤다. 교사 역량도 중요하다. 한 대학의 사례에 따르면 AI 평가 교육을 받은 교사는 AI 과제 평가에 대한 자신감이 26%에서 81%로 상승했다. 교사의 이해도가 높을수록 학생의 AI 활용도 책임 있게 이뤄진다. 또한 과제에서 AI 활용 비중이 높을수록 구술 평가나 실습 과제를 늘리는 방식도 필요하다. 단순히 글을 쓰는 데 그치지 않고, 작성한 내용을 설명하고 방어하는 과정을 통해 사고력 훈련이 이뤄질 수 있다.
사고의 시대, 평가도 바뀌어야
ChatGPT가 구글을 앞서 지식 탐색의 출발점이 되었지만, 여전히 일정 수준의 오류를 발생시킨다는 사실은 교육에 새로운 과제를 던진다. 그러나 이를 단순한 결함으로 볼 필요는 없다. 실제 사용자들은 초안을 빠르게 구성할 수 있는 도구로 ChatGPT를 활용하되, 최종 판단은 자신이 직접 내리고 있다. 이처럼 ChatGPT는 사고를 대신하는 것이 아니라, 사고를 유도하는 보조 도구로 기능할 수 있다. 단, 그 전제는 분명하다. 생성된 결과물이 자동으로 신뢰를 얻는 것은 아니며, 인간의 검토와 판단이 반드시 따라야 한다는 점이다. 초안은 빠르게 만들 수 있지만, 정확성과 의미는 여전히 학습자가 책임져야 한다. 이제는 이런 사용 방식을 교육제도에 반영할 때다. 투명성 확보, 자기 점검, 교사 역량 강화 같은 실질적 조치를 통해, 오늘의 실험을 내일의 기준으로 바꿔야 한다. 기술은 빠르게 진화하지만, 신뢰는 반드시 검증을 통해서만 쌓인다. 지금 필요한 건, AI와 인간의 역할을 명확히 나누는 일이다.
본 연구 기사의 원문은 Draft Faster, Think Deeper: Why ChatGPT Belongs at the Start—Not the End—of Serious | The Economy 를 참고해주시기 바랍니다. 2차 저작물의 저작권은 The Economy Research를 운영 중인 The Gordon Institute of Artificial Intelligence에 있습니다.