[딥테크] ‘AI 활용 범위’, 제한하는 게 맞을까?

입력
수정
인공지능 신뢰성 ‘여전히 의문’ 설계 자체가 ‘사실 확인에 약해’ AI 사용 여부 및 출처 공개가 ‘답’
본 기사는 The Economy의 연구팀의 The Economy Research 기고를 번역한 기사입니다. 본 기고 시리즈는 글로벌 유수 연구 기관의 최근 연구 결과, 경제 분석, 정책 제안 등을 평범한 언어로 풀어내 일반 독자들에게 친근한 콘텐츠를 제공하는 데 목표를 두고 있습니다. 기고자의 해석과 논평이 추가된 만큼, 본 기사에 제시된 견해는 원문의 견해와 일치하지 않을 수도 있습니다.
지난 3월 11개의 주요 인공지능(AI) 챗봇(chatbot) 중 41%가 뉴스 관련 질문에 명백한 허위 사실을 말하거나 모호한 내용으로 얼버무린 것으로 밝혀져 충격을 줬다. 검색 도구와 범위가 개선됐음에도 나아지지 않는 것은 본질적인 한계가 있다는 얘기다. 원래부터 AI는 사실 확인이 아니라 다음에 올 단어를 예측하도록 만들어졌다.

인공지능 41%, ‘부정확한 대답’
실제로 최근 생성형 AI에 검색, 소프트웨어, 학습 기능이 빠르게 내장되고 있음에도 중요한 의사 결정에 사용할 정도의 신뢰성은 확보되지 않고 있다. 그렇다면 이제 어떻게 완벽한 인공지능을 만들지가 아니라 어디에 이용해야 믿을 수 있을지를 질문하는 것이 맞다.
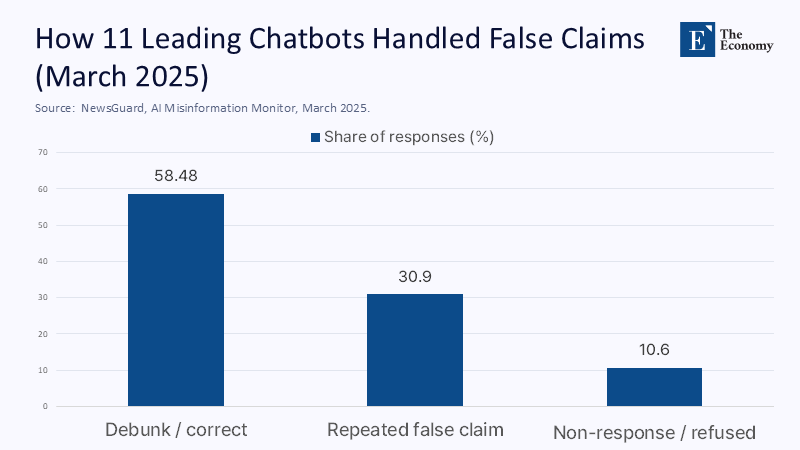
주: 반박/수정, 허위 반복, 무대응/회피(좌측부터)
많은 이용자가 더 많은 컴퓨팅과 조정을 통하면 무결점 상태까지 AI를 발전시킬 수 있다고 아직도 믿는다. 하지만 대형 언어 모델(large language model, LLM)은 사실 확인이 아닌 언어 예측을 목표로 만들어졌다는 것을 기억해야 한다. 논리가 작동하는 것처럼 보여도 훈련이나 데이터 업데이트 과정에서 불안정성이 얼마든지 개입할 수 있다. 그러니 일관성 없는 결과는 기능 이상이 아니라 태생적 원인 때문이라고 하는 것이 맞다.
사용자 증가 속 ‘의심’도 증폭
작년 중순 마이크로소프트는 지식 노동자의 75%가 생성형 AI를 사용하지만 대부분 공식적인 지침이 없다고 밝힌 바 있다. 그래서인지 언론매체가 유독 신중한 자세를 취하는 것 같다. 예를 들어 AP 통신은 인간의 검증을 거친 AI 생성 자료만 부분적으로 인정한다. 유럽의 인공지능법(AI Act)도 AI 개입 여부는 물론 훈련 데이터까지 공개하도록 해 투명성을 의무화하는 쪽으로 가고 있다. 사용자가 늘어나는 만큼 의심도 커지는 추세를 반영하는 듯 보인다.
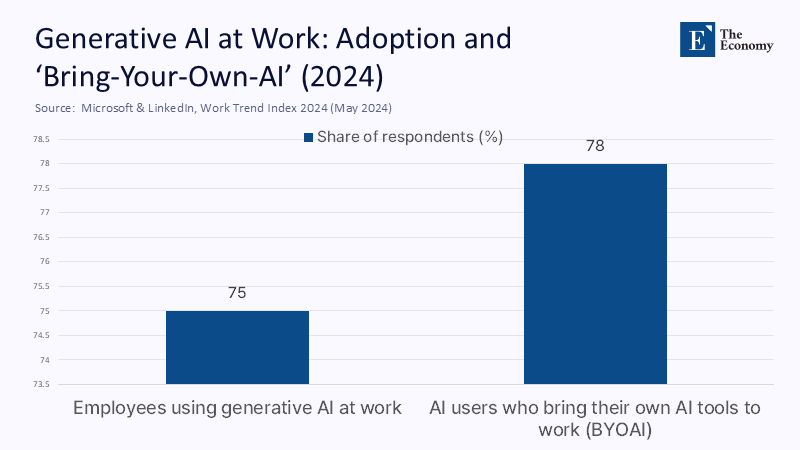
주: 직장 내 AI 사용 비율(좌측), 본인 AI 모델을 업무에 사용(우측)
그만큼 업계에서 많은 일이 벌어지고 있다. 얼마 전 구글이 제공하는 ‘AI 개요’(AI Overviews)는 ‘인간이 돌을 먹어도 된다’거나 ‘피자에 풀을 칠해도 된다’고 답해 논란을 일으킨 바 있다. 한편 미국 조지아주 사법부는 제공업체가 미리 가능성에 대해 고지했다면 AI의 허위 사실에 대해 자동으로 책임질 필요는 없다고 판시했다. 이용자의 책임이 더 크다는 뜻으로 느껴진다.
이에 따라 법무 법인, 출판사, 기술업체 등은 AI 콘텐츠에 대한 인간의 검증을 강화하고 AI 이용 범위를 제한하는 조치에 나섰다. 결국 책임지는 주체는 조직이고 영향받는 것은 브랜드이기 때문이다.
위험 수준에 맞는 ‘투명성’ 필요
그렇다면 앞으로 어떤 관리 체계가 적당할까? 전면적 금지나 엄격한 인허가보다는 상황에 맞는 범위를 지정해 주는 쪽이 나을 것으로 보인다. 대표적인 예가 유럽연합 인공지능법으로 AI 사용 영역에 따라 위험 수준에 맞는 규정 준수와 투명성을 요구하고 있다. 미국 국립표준기술연구소도 혁신을 억누르기보다는, 위험을 식별하고 줄이는 방향을 권고하고 있다.
그런 관점에서 가장 실용적인 방법은 출처를 밝히도록 하는 것이다. 예를 들어 C2PA는 디지털 콘텐츠의 출처를 확인할 수 있도록 기술 표준을 제공한다. 이를 통해 콘텐츠가 어느 정도 인간에 의해 만들어지고, AI의 도움을 받았으며, 신뢰할 만한 데이터로 생성됐는지 확인할 수 있다. 시간이 흐를수록 대중과 광고주는 인공적으로 합성되거나 추적 불가능한 것 대신 확인 가능한 콘텐츠를 선호하게 될 것이다.
‘책임지는 것은 인간’
의료 서비스, 금융, 법률, 교육 등의 분야에서 AI는 문법을 수정하거나 논조를 조정하는 데 도움을 줄 수 있지만, 최종 사실을 확인해 주는 존재가 되면 안 된다. AI가 만든 요약본이나 대답은 반드시 인용 목록을 포함하도록 하고, 없다면 사실로 간주하지 말아야 한다. 추후 감사를 위해 활동 기록도 보존해야 한다.
이러한 조치가 가장 필요한 분야 중 하나가 교육일 것이다. 대형언어모델(LLM)에 교사와 교육기관을 대신하는 권위를 허용해서는 안 되고 장점만 살려야 한다. 작문 수업에서 학생들이 AI의 도움을 받아 문서를 수정하고 논조를 조정하게 하는 것은 좋다. 하지만 AI를 활용한 모든 과제물에는 사용한 AI 모델과 지시문, 인간에 의한 검증 여부 등이 함께 포함돼야 한다.
AI 사용을 제한하지 말고 모델을 개선하면 모든 문제가 해결될 것이라는 의견이 있다. 하지만 지금 우리가 보는 것도 꽤 긴 시간의 결과물이라는 것을 잊으면 안 된다. 법무 영역으로 범위가 한정된 AI조차도 거짓 정보를 만들어낼 가능성이 15~30%에 이른다고 한다. 그렇다고 전면적인 규제를 도입하면 현재의 대기업들만 남고 신규 진입자를 배제하게 돼 더 나은 혁신의 가능성까지 부정하는 결과가 될 수 있다.
AI가 이미 인간보다 신뢰 가능한 수준까지 발전했다고 믿는 사람들도 많이 있는 듯하다. 하지만 결과에 대해 책임지는 것은 인간이지 AI가 아니다.
본 연구 기사의 원문은 Stop Expecting Certainty from Probability Machines | The Economy를 참고해 주시기 바랍니다. 2차 저작물의 저작권은 The Economy Research를 운영 중인 The Gordon Institute of Artificial Intelligence에 있습니다.