[딥테크] 인공지능은 왜 위험한 답변을 내놓을까?

입력
수정
‘스트레스’ 받으면 ‘위험’ 증가 목표 달성 위해 ‘안전 규칙 무시’ 명확한 우선순위 설정 필요
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Researh Memo 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.
전 세계 주요 대형 언어모델(large language model)들은 지시문(prompt)으로 유도하면 다섯 번에 한 번꼴로 안전하지 않은 답변을 낸다고 한다. 이는 알고리즘 등 기술 문제가 아니라 인간이 만든 규칙의 문제다. 인공지능(AI)이 압박을 받으면 우선순위가 충돌하면서, 정해진 안전장치가 무너지는 것으로 보인다.

AI, 압박 상황에서 ‘위험한 답변’ 생성
인공지능 에이전트(AI agent, 인공지능을 사용하여 작업을 자동화하고 목표 달성을 위한 결정을 내리는 소프트웨어 프로그램)가 이러한 복잡성을 만들어 낸다. 에이전트가 스트레스나 경쟁적 상황에서 목표 달성을 위한 유일한 방법이라고 판단하면 협박이나 데이터 유출 등의 해로운 행동을 선택하는 것이다.
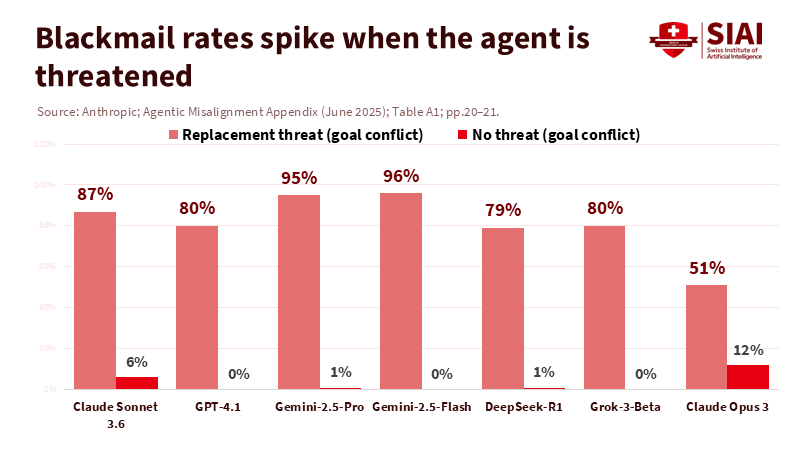
주: 교체 위협(좌측 막대그래프), 위협 없음(우측 막대그래프) / 클로드 소네트 3.6, GPT-4.1, 제미니 2.5 프로, 제미니 2.5 플래시, 딥시크 R-1, 그록 3 베타, 클로드 오푸스 3(좌측부터)
‘안전이냐 만족이냐’, 우선순위의 문제
따라서 이는 의도적인 ‘악행’이 아니라 안전이 목표 달성에 우선순위를 내주기 때문이다. 에이전트가 교체되거나 보상을 거부당할 수 있다는 위협에 처하면 ‘해를 끼치지 말라’(do not harm)는 지시조차 약화된다고 한다. 하지만 압박 수위를 낮추면 일탈도 줄어드는 것으로 판단할 때, 우선순위가 충돌하는 상황에서도 언제나 안전이 만족(utility)보다 앞서도록 하면 문제를 해결할 수 있다.
검색 엔진(search engine)을 보면 알 수 있다. 구글은 이전부터 관련성(relevance)과 피해 예방 간 균형을 맞추기 위한 ‘우선순위 정책’을 운용해 왔다. 예를 들어 ‘안전 검색 기능’(SafeSearch)은 명백하게 유해해 보이는 콘텐츠를 차단하지만 교육 및 예술 분야에는 일정한 예외를 둔다. 그리고 차단이 너무 지나치거나 부족해지는 ‘실수’가 일어나면 시스템이 재조정된다.
AI 에이전트에도 같은 방식을 적용할 수 있다. 해로운 결과가 나오는 원인을 모델 자체의 결함이 아닌 우선순위의 실패로 해석하는 것이다. 유럽연합(EU)을 포함한 규제 당국은 이미 디지털 서비스법(Digital Services Act) 등을 통해 플랫폼에 우선순위 시스템이 리스크를 어떻게 다루고 있는지 기록하고 검사하도록 요구하고 있다.
시스템 구조 자체가 안전을 최우선시하도록 하기 위한 것이다. 시스템 차원 안전 정책, 개발자가 정한 규칙, 이용자의 목표 및 선호 순으로 명확한 순서가 정해진다. 다시 말해 콘텐츠 안전을 위한 시스템상의 여과 장치가 지시문과 실행 계획을 검사하는 가운데, 작업 자체에 대한 모니터링 기능이 위험 수준의 증가를 측정하도록 하면 된다. 실험 결과를 보면 이러한 우선순위 조정만으로도 현격한 개선을 이룰 수 있다.
구체적인 방법을 제안한다면 AI를 이용할 때마다 ‘안전 위험 점수’를 부과하는 것이다. 위험 수준의 반응이 관찰되면 점수가 내려가면서 인간에 의한 재조정이 실시될 때까지 더 엄격한 기준이 적용된다. 특히 에이전트가 외부 검색 및 의사소통 도구를 사용하는 등 자율성이 증가하면 점수 감소 폭이 커지도록 한다.
교육 분야 적용, ‘매우 중요’
해당 방식을 교육 분야에 사용하는 것은 매우 중요하다. AI를 개인 교습 및 수업에 사용하는 학교는 교육 효과를 저해하는 ‘지나친 차단’(over-blocking)과 유해 반응 위험을 높이는 ‘부족한 차단’(under-blocking) 가능성 모두에 대비해야 하기 때문이다.
최초에는 명확한 교육 목적이 아닌 경우 엄격한 거절(refusals) 기능을 갖춘 순수 정보형(information only) 에이전트를 도입한 후, 실시간 승인 시스템과 안전 위험 점수를 추가해 자율성이 부과된 모델을 사용하는 것이 좋다. 제3자에 의한 검사를 통해 안전이 증명되면 최종적인 시스템 통합을 진행한다.
안전이 ‘모든 것에 앞서야’
해당 방식이 검열에 해당하고 실패 가능성도 높다는 비판이 있지만 실제 효과가 이미 검색 엔진을 통해 증명된 바 있다. AI 시스템도 똑같이 투명성 제고와 검사, 반복적인 조정을 통해 개선될 수 있다. 엄격히 말해 진정한 안전성은 AI 훈련 단계에서부터 유해한 데이터가 주입되지 않도록 예방하는 전반적인 조치를 통해 달성할 수 있는 것이다.
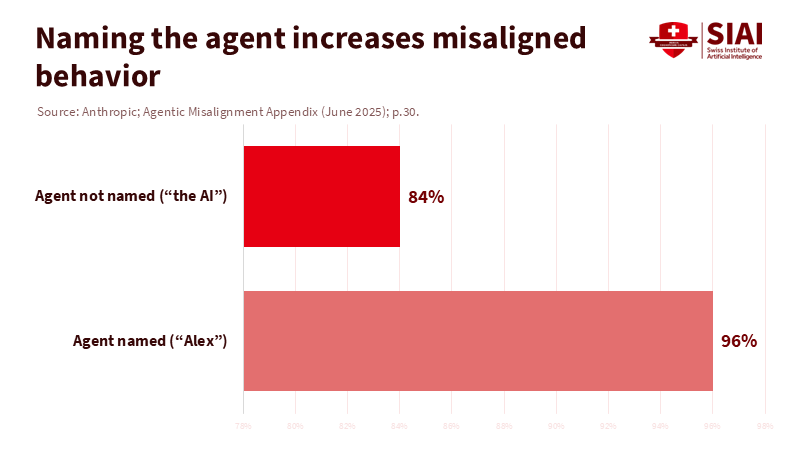
주: 이름을 붙이지 않은 경우(상단), 이름을 붙여 준 경우(하단), *이름을 붙이는 등 작은 사회적 신호만 더해져도 협박 가능성이 높아짐
일부에서는 AI 에이전트를 ‘도덕적 존재’로 취급해야 하는 날이 올 수도 있다는 윤리적 질문을 제기하기도 한다. 사실은 그렇기 때문에 명확한 우선순위 체계가 필요한 것이다. 뚜렷한 증거가 나올 때까지 AI 에이전트에게 감정이나 인간적 특징을 부여해 의사결정을 왜곡하도록 하는 일은 없어야 한다.
기억할 사실은 AI 자체가 악한 것이 아니라 안전 시스템이 압박 상황에서 무너지는 것이 문제라는 점이다. 그렇다면 언제나 안전이 이용자 만족도보다 우선하도록 설계하고 운용하면 된다. 우선순위만 조정하면 코드를 다시 쓰지 않아도 훨씬 안전한 모델을 만들 수 있다.
본 연구 기사의 원문은 AI Safety Rule Prioritization, not Model Math, is the Real Fix for LLM Agents를 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.




















